Shredding Overview
caution
You are reading documentation for an outdated version. Here’s the latest one!
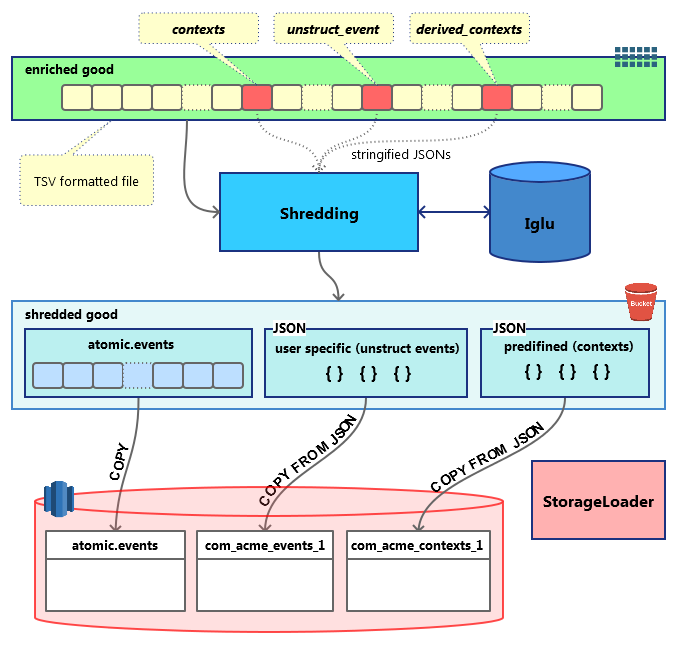
Shredding is the process of splitting a Snowplow enriched event into several smaller files, which can be inserted directly into Redshift tables.
A Snowplow enriched event is a 131-column TSV file, produced by Enrich. Each line contains all information about a specific event, including its id, timestamps, custom and derived contexts and much more.
After shredding, the following entities are split out from the original event:
- Atomic events. a TSV line very similar to
EnrichedEventbut not containing JSON fields (contexts,derived_contextsandunstruct_event). The results will be stored in a path similar toshredded/good/run=2016-11-26-21-48-42/atomic-events/part-00000and will be available to load via RDB Loader or directly via Redshift COPY. - Contexts. This part consists of the two extracted above JSON fields:
contextsandderived_contexts, which are validated (during the enrichment step) self-describing JSONs. But, unlike the usual self-describing JSONs consisting of aschemaand adataobject, these ones consist of aschemaobject (like in JSON Schema), the usualdataobject and ahierarchyobject. Thishierarchycontains data to later join your contexts’ SQL tables with theatomic.eventstable. The results will be stored in a path which looks likeshredded/good/run=2016-11-26-21-48-42/shredded-types/vendor=com.acme/name=mycontext/format=jsonschema/version=1-0-1/part-00000, where the part files likepart-00000are valid NDJSONs and it will be possible to load them via RDB Loader or directly via Redshift COPY. - Self-describing (unstructured) events. Very much similar to the contexts described above those are the same JSONs with the
schema,dataandhierarchyfields. The only difference is that there is a one-to-one relation withatomic.events, whereas contexts have many-to-one relations.
Those files end up in S3 and are used to load the data into Redshift tables dedicated to each of the above files under the RDB Loader orchestration.
The whole process could be depicted with the following dataflow diagram.