RDB Loader 1.0.0
1. Overview
Enriched events are loaded from S3 to Redshift by the RDB loader, which is in fact made of 2 applications:
- Shredder: Spark batch job reading enriched events from S3 and writing shredded data to S3. Needs to be orchestrated by an external app (e.g. dataflow-runner). When shredder is done, it writes a message to SQS with the details about shredded data on S3. Each execution writes one message to SQS.
- Loader: long-running app that consumes details about shredded data from SQS and inserts into Redshift
Upstream of the RDB loader, S3 loader must be setup to write enriched events from Kinesis to S3. It's important to not partition when doing so (these parameters must not be set).
2. Architecture
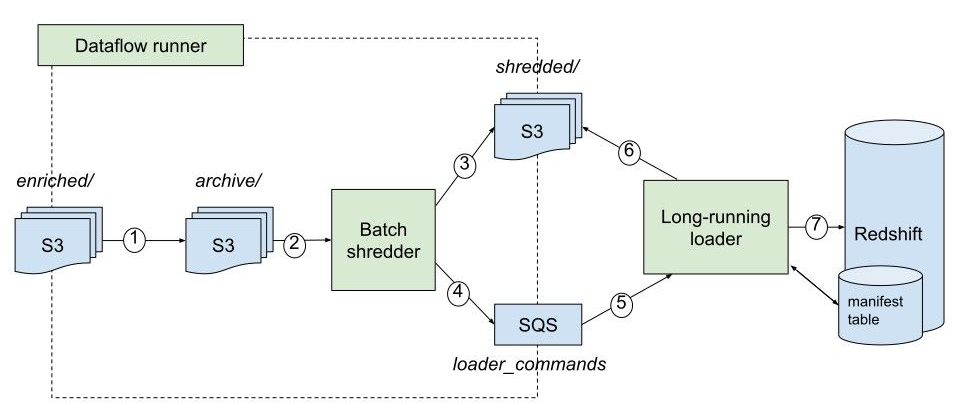
- Enriched files copied from enriched/ to archive/enriched/ with S3DistCp on EMR.
- Shredder is run as an EMR step. It reads the directory from step 1.
Step 1 and 2 are orchestrated by Dataflow Runner (or any other orchestration tool).
Shredder is stateless. It knows which data to shred by comparing directories in archive/enriched/ and shredded/. - Shredder writes shredded data to S3.
- When the writing is done, it sends the metadata about shredding data to SQS with this schema.
- Loader in a long-running app running app (e.g. on ECS fargate) that consumes messages from SQS.
- When it receives a message sent by shredder, it knows where shredded data to load is located on S3.
- Loader loads data into Redshift. It uses a manifest table to prevent from double-logging and for better logging.
3. Setup
Steps to get RDB loader up and running:
- Configure Transformer (formerly Shredder) and loader
- Create SQS FIFO queue. Content-based deduplication needs to be enabled.
- Configure Iglu Server with the schemas
IMPORTANT: do not forget to add/apiat the end of the uri in the resolver configuration for the loader - Create
atomic.eventstable. - Run RDB Loader as long-running process with access to message queue:
docker run snowplow/snowplow-rdb-loader:1.0.0 --config config.hocon.base64 --iglu-config resolver.json.base64 - Schedule EMR jobs with S3DistCp and Shredder
4. Shredder stateless algorithm
Shredder is stateless and infers automatically which data need to get shredded and which data were not successfully shredded in past runs, by comparing the content of enriched and shredded folders on S3.
How does this work ?
Inside archive/enriched/, folders are organized by run ids, e.g.

When shredder starts, it lists the content of archive/enriched/.
It then lists the content of shredded/ and compares.
If all enriched events in archive/enriched/ have already been successfully shredded, then each folder in archive/ must exist in shredded/ with the same name and inside each of them, a file shredded_complete.json must exist. The content of this file is a SDJ with this schema and is exactly what is sent to SQS for the loader.
When a folder exists in archive/enriched/ but not in shredded/, it means that the folder needs to get shredded.
If a folder exists in both archive/ and shredded/ but there is no shredded_complete.json in shredded/, it means that shredded has failed for this folder in a past run. In this case shredder logs an error.
IMPORTANT: when rolling out to this version, the existing state needs to get "sealed", by creating shredded_complete.json file (can be empty) inside each folder in shredded/.